Physicist: There’s a long history of big things in the solar system slamming into each other. Recently (the last 4.5 billion years or so) there haven’t been a lot of planetary collisions, but there are still lots of “minor” collisions like the Chicxulub asteroid 65 million years ago that caused that whole kerfuffle (65,000,000 years is practically this morning compared to the age of the solar system), or comet Shoemaker Levy 9 which uglied up Jupiter back in 1994.

Jupiter after a run-in with Shoemaker Levy 9. Each of those black clouds on the lower right is caused by the impact of a different chunk of the same comet, and each is bigger than Earth.
So while planets slamming or nearly slamming into each other isn’t a serious concern today, it was at one time. Of course, in solar systems where this is still a serious concern, there’s unlikely to be anything alive to do the concerning.
For the sake of this post, let’s say there’s another planet, “Htrae”, that is the same size and approximate composition of Earth (but possibly populated entirely with evil goatee-having doppelgangers with reversed names).
A direct impact, or even a glancing impact, is more or less what you might expect: you start with two planets and end with lots of hot dust. We’re used to impacts that dent or punch through the crust of the Earth, but really big impacts treat both planets like water droplets. Rather than crushing together like lumps of clay, Earth and Htrae would “splash” off of each other. A direct impact of two like-masses tends to destroy them both. A glancing, well-off-center, impact will “stir” both planets, leaving no none of the original surface on either. A glancing impact like this is the best modern theory of the origin of the Moon.
If Htrae were to fall out of the sky, it would probably hit the Earth with a speed that’s on the same scale as Earth’s escape velocity: 11 km/s (Probably more). The time between when Htrae appears to be about the same size as the Sun or Moon, to when it physically hits the surface, would be a couple of weeks (give or take a lot). The time between hitting the top of the atmosphere and hitting the bottom would be a few seconds. If you were around, you would see Htrae spanning from one horizon to the other. A few moments before impact the collective atmospheres of both planets would glow brightly as they are suddenly compressed. It’s more likely that in those last few seconds/moments you would be vaporized from a distance by the heat and light released by the impact, and less likely that you would be crushed. People on the far side of Earth wouldn’t fare much better. They’d get very little warning, and would have to suddenly deal with the ground, and everything on it, suddenly being given a kick from below big enough to go flying into space.
Generally speaking, being slapped by the ground so hard that you find yourself in deep space a few minutes later is seriously fatal.
A near miss is a lot less flashy, but you really wouldn’t want to be around for that either. When you’re between two equal masses, you’re pulled equally by both. You may be standing on the surface of Earth, but most of it is still a long way away (about 4,000 miles on average). So if Htrae’s surface was within spitting distance, then you’d be about 4,000 miles from most of it as well. Nothing on the surface of Earth has any special “Earth-gravity-solidarity”, so if you were “lucky” enough to be standing right under Htrae as it passed overhead, you’d find yourself in nearly zero gravity.
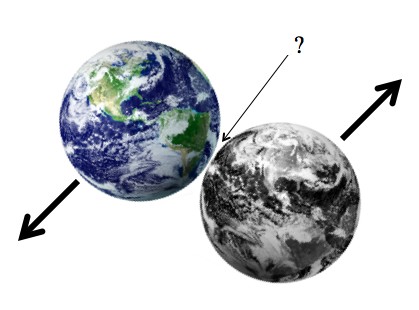
Earth and Htrae have an extremely near miss. Which way does the gravity between them point?
Of course, there’s nothing special about stuff that’s on the surface either. The surface itself would also start floating around, and the local atmosphere would certainly take the opportunity to wander off. On a large scale this is described by the planets being well within each others’ Roche limit, which means that they literally just kinda fall apart. It’s not just that the region between the planets is in free fall, it’s that halfway around the worlds gravity will suddenly be pointing sideways quite a bit. So, what does a land-slide the size of a planet look like? From a distance it’s likely to be amazing, but you’re gonna want that distance to be pretty big.
Even a near miss, with the planets never quite coming into contact, does a colossal amount of damage. There would be a cloud of debris between and orbiting around both planets (or rather around both “roiling molten masses”) as well as long streamers of what used to be ocean, crust, and mantle extending between them as they move apart. This has never been seen on a planetary scale, since all the things doing the impacting these days barely have their own gravity. The highest vertical leap on a comet would be infinity (if anyone were to try).
But the news gets worse. Unless both planets have a good reason to be really screaming past each other (maybe they were counter-orbiting or Htrae fell inward from the outer solar system or something), a near miss is usually just a preamble for a direct impact. All of the damage and scrambling that Earth and Htrae did do each other took energy. That energy is taken mostly from the kinetic energy, so after a near miss the average speed of the two planets would be less than it was before. And that means that the planets often can’t escape from each other (at least not forever). In fact, this is why Shoemaker Levy 9 impacted Jupiter a dozen times instead of all at once. Before impacting, the comet had passed within Jupiter’s Roche limit (probably several times), been pulled into a streamer of rocks, and slowed down.
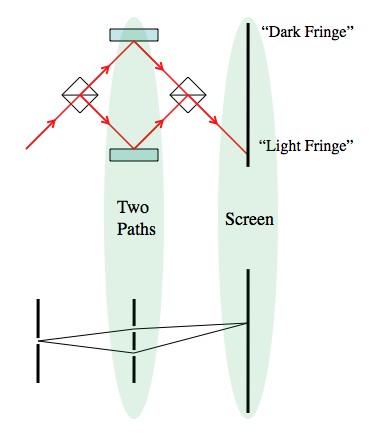
 ” and if it’s taking the top path it’s in the state “
” and if it’s taking the top path it’s in the state “ “. Beam splitters take
“. Beam splitters take ") , and take
, and take ") .
.=\frac{1}{\sqrt{2}}\left(H|b\rangle+H|t\rangle\right)=\frac{1}{2}\left(|b\rangle+|t\rangle+|b\rangle-|t\rangle\right)=|b\rangle") . This is exactly the situation in the top most picture!
. This is exactly the situation in the top most picture! means that each of the states has a 1/2 chance of being seen if the photon were detected (it has a 50/50 chance of being seen on either path).
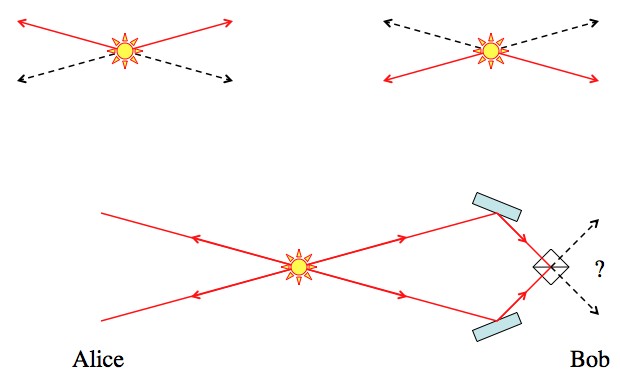
means that each of the states has a 1/2 chance of being seen if the photon were detected (it has a 50/50 chance of being seen on either path).") ” thing is a superposition of the top and bottom paths, which interferes at the second beam splitter. So, hopefully, each of the entangled photons will be in that same state and will interfere similarly, with similar results. Unfortunately, that’s not the case even a little.
” thing is a superposition of the top and bottom paths, which interferes at the second beam splitter. So, hopefully, each of the entangled photons will be in that same state and will interfere similarly, with similar results. Unfortunately, that’s not the case even a little.") ; a combination of “both up” and “both down”. The subscripts, A or B, indicate which photon goes to which person, Alice or Bob.
; a combination of “both up” and “both down”. The subscripts, A or B, indicate which photon goes to which person, Alice or Bob.\\=\frac{1}{\sqrt{2}}\left(|b\rangle_AH_B|b\rangle_B+|t\rangle_AH_B|t\rangle_B\right)\\=\frac{1}{\sqrt{2}}\left(\frac{1}{\sqrt{2}}|b\rangle_A(|b\rangle_B+|t\rangle_B)+\frac{1}{\sqrt{2}}|t\rangle_A(|b\rangle_B-|t\rangle_B)\right)\\=\frac{1}{2}\left(|b\rangle_A(|b\rangle_B+|t\rangle_B)+|t\rangle_A(|b\rangle_B-|t\rangle_B)\right)\\=\frac{1}{2}\left(|b\rangle_A|b\rangle_B+|b\rangle_A|t\rangle_B+|t\rangle_A|b\rangle_B-|t\rangle_A|t\rangle_B\right)\\=\frac{1}{2}\left(|b\rangle_A+|t\rangle_A\right)|b\rangle_B+\frac{1}{2}\left(|b\rangle_A-|t\rangle_A\right)|t\rangle_B\end{array}")
|b\rangle_B") or
or |t\rangle_B") . As far as Bob is concerned, that means that there’s a 50/50 chance of detecting it on either path. No interference.
. As far as Bob is concerned, that means that there’s a 50/50 chance of detecting it on either path. No interference.") . All 4 of these states are equally likely (since,
. All 4 of these states are equally likely (since,  ). If Alice looks and sees the photon on either path, then two of those four states will collapse*. If she sees the photon in the top path, then the state of the system becomes
). If Alice looks and sees the photon on either path, then two of those four states will collapse*. If she sees the photon in the top path, then the state of the system becomes ") and if she see’s it on the bottom path, then the state of the system becomes
and if she see’s it on the bottom path, then the state of the system becomes ") . In both cases, Bob has a 50/50 chance of seeing it on either path. No interference!
. In both cases, Bob has a 50/50 chance of seeing it on either path. No interference!") and
and ") are fundamentally different, it’s just that Bob won’t know which he has until Alice tells him the result of her measurement (by calling or writing or something). This is actually the basis behind
are fundamentally different, it’s just that Bob won’t know which he has until Alice tells him the result of her measurement (by calling or writing or something). This is actually the basis behind \rangle") . If she looks and sees the photon in the top path, then suddenly she’ll be in the state
. If she looks and sees the photon in the top path, then suddenly she’ll be in the state \rangle") . That isn’t particularly profound. When things interact they’re each affected, and in this case the effect on Alice is remembering that the photon took the top path (also maybe a commemorative lab party with top hats). The “just go ahead and Look at the particle” operation, L, does this:
. That isn’t particularly profound. When things interact they’re each affected, and in this case the effect on Alice is remembering that the photon took the top path (also maybe a commemorative lab party with top hats). The “just go ahead and Look at the particle” operation, L, does this: \rangle |t\rangle_A\right) = |A(t)\rangle |t\rangle_A") . The same idea for
. The same idea for \rangle\left(|t\rangle_A|t\rangle_B + |b\rangle_A|b\rangle_B\right)|B(?)\rangle") . Alice and Bob are both in one state, from each of their points of view. Now say Alice looks (that means “apply
. Alice and Bob are both in one state, from each of their points of view. Now say Alice looks (that means “apply  “).
“).![\begin{array}{ll}L_A\frac{1}{\sqrt{2}}|A(?)\rangle\left(|t\rangle_A|t\rangle_B + |b\rangle_A|b\rangle_B\right)|B(?)\rangle\\[2mm]=L_A\frac{1}{\sqrt{2}}\left(|A(?)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(?)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(b)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B + |A(b)\rangle|b\rangle_A|b\rangle_B\right)|B(?)\rangle\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bll%7DL_A%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%7CA%28%3F%29%5Crangle%5Cleft%28%7Ct%5Crangle_A%7Ct%5Crangle_B+%2B+%7Cb%5Crangle_A%7Cb%5Crangle_B%5Cright%29%7CB%28%3F%29%5Crangle%5C%5C%5B2mm%5D%3DL_A%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%5Cleft%28%7CA%28%3F%29%5Crangle%7Ct%5Crangle_A%7Ct%5Crangle_B%7CB%28%3F%29%5Crangle+%2B+%7CA%28%3F%29%5Crangle%7Cb%5Crangle_A%7Cb%5Crangle_B%7CB%28%3F%29%5Crangle%5Cright%29%5C%5C%5B2mm%5D%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%5Cleft%28%7CA%28t%29%5Crangle%7Ct%5Crangle_A%7Ct%5Crangle_B%7CB%28%3F%29%5Crangle+%2B+%7CA%28b%29%5Crangle%7Cb%5Crangle_A%7Cb%5Crangle_B%7CB%28%3F%29%5Crangle%5Cright%29%5C%5C%5B2mm%5D%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%5Cleft%28%7CA%28t%29%5Crangle%7Ct%5Crangle_A%7Ct%5Crangle_B+%2B+%7CA%28b%29%5Crangle%7Cb%5Crangle_A%7Cb%5Crangle_B%5Cright%29%7CB%28%3F%29%5Crangle%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{ll}L_A\frac{1}{\sqrt{2}}|A(?)\rangle\left(|t\rangle_A|t\rangle_B + |b\rangle_A|b\rangle_B\right)|B(?)\rangle\\[2mm]=L_A\frac{1}{\sqrt{2}}\left(|A(?)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(?)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(b)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B + |A(b)\rangle|b\rangle_A|b\rangle_B\right)|B(?)\rangle\end{array}")
\rangle|t\rangle_A|t\rangle_B|B(?)\rangle") . Bob hasn’t look at his particle yet, but when he does he’ll see it in the top state. From this Alice’s perspective, the state of Bob’s particle has undergone “wave function collapse” into the top state. In exactly the same way, the version of Alice that saw her particle in the bottom state will find that Bob’s particle “collapsed” to the bottom state. They both saw a
. Bob hasn’t look at his particle yet, but when he does he’ll see it in the top state. From this Alice’s perspective, the state of Bob’s particle has undergone “wave function collapse” into the top state. In exactly the same way, the version of Alice that saw her particle in the bottom state will find that Bob’s particle “collapsed” to the bottom state. They both saw a ![\begin{array}{ll}L_B\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(b)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=|A(t)\rangle|t\rangle_A|t\rangle_B|B(t)\rangle\\[2mm]\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bll%7DL_B%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%5Cleft%28%7CA%28t%29%5Crangle%7Ct%5Crangle_A%7Ct%5Crangle_B%7CB%28%3F%29%5Crangle+%2B+%7CA%28b%29%5Crangle%7Cb%5Crangle_A%7Cb%5Crangle_B%7CB%28%3F%29%5Crangle%5Cright%29%5C%5C%5B2mm%5D%3D%7CA%28t%29%5Crangle%7Ct%5Crangle_A%7Ct%5Crangle_B%7CB%28t%29%5Crangle%5C%5C%5B2mm%5D%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{ll}L_B\frac{1}{\sqrt{2}}\left(|A(t)\rangle|t\rangle_A|t\rangle_B|B(?)\rangle + |A(b)\rangle|b\rangle_A|b\rangle_B|B(?)\rangle\right)\\[2mm]=|A(t)\rangle|t\rangle_A|t\rangle_B|B(t)\rangle\\[2mm]\end{array}") . For both versions of both Alice and Bob, the whole process was random, and the only thing they’ll notice, if they ever compare notes, is that they measured the same thing.
. For both versions of both Alice and Bob, the whole process was random, and the only thing they’ll notice, if they ever compare notes, is that they measured the same thing.





 is the unique number such that
is the unique number such that  = \left(\frac{1}{A}\right)A = 1") “. This one definition is the headwaters for all of the properties of rational numbers that follow. If ever you’re totally stuck, and don’t know how to handle fractions, keep this single and tremendously important definition in mind. Everything else follows (but maybe not immediately). Just a quick warning for those of you expecting any of the rest of this post be about history or something interesting; everything that follows is a dry-as-bones, utterly literal, derivation of the arithmetic rules for fractions and rational numbers from the ground up. Definitely boring, but worth seeing once.
“. This one definition is the headwaters for all of the properties of rational numbers that follow. If ever you’re totally stuck, and don’t know how to handle fractions, keep this single and tremendously important definition in mind. Everything else follows (but maybe not immediately). Just a quick warning for those of you expecting any of the rest of this post be about history or something interesting; everything that follows is a dry-as-bones, utterly literal, derivation of the arithmetic rules for fractions and rational numbers from the ground up. Definitely boring, but worth seeing once. = \frac{B}{A}") . This is strictly a convention; a standard defined notation that’s agreed upon.
. This is strictly a convention; a standard defined notation that’s agreed upon.") .
.\frac{1}{6}") .
.4 = 3\left(\frac{1}{4}\right)4 = 3\cdot 1 = 3") . We can even do a little better and say
. We can even do a little better and say  = BC\left(\frac{1}{A}\right) = \frac{BC}{A}") .
. .
.\left(\frac{1}{B}\right) = ?") . But check this out:
. But check this out: \left(\frac{1}{B}\right)AB = \left(\frac{1}{A}\right)A\left(\frac{1}{B}\right)B = 1\cdot 1 = 1") . This means that
. This means that \left(\frac{1}{B}\right)") does the exact same thing that
does the exact same thing that  does, and (since this is all there is in the definition) in fact is the same. So,
does, and (since this is all there is in the definition) in fact is the same. So,  .
.\left(\frac{1}{3}\cdot3\right) = 1") . But keep in mind that “
. But keep in mind that “ is the unique number such that
is the unique number such that  = \left(\frac{1}{15}\right)15 = 1") “, and since
“, and since  has been shown to have the same property we know that
has been shown to have the same property we know that  . This may seem anal-retentive and unnecessary, but that’s how math is done.
. This may seem anal-retentive and unnecessary, but that’s how math is done. = AC\frac{1}{BD} = \frac{AC}{BD}") . In other words “fractions multiply across”.
. In other words “fractions multiply across”. . Deriving the rules is often complex, but using them isn’t.
. Deriving the rules is often complex, but using them isn’t. . This means two things: fractions can be reduced, and multiplying the top and the bottom by the same thing does nothing.
. This means two things: fractions can be reduced, and multiplying the top and the bottom by the same thing does nothing. .
. = \frac{A+C}{B}") . So now, if the fractions have the same denominator, then they can be added together.
. So now, if the fractions have the same denominator, then they can be added together.
\frac{1}{BD} = \frac{AD+BC}{BD}")

}") is the unique number such that
is the unique number such that }\right) = \left(\frac{1}{\left(\frac{A}{B}\right)}\right)\frac{A}{B} = 1") “.
“. . Since
. Since  does exactly what
does exactly what } = \frac{B}{A}") .
.} = \frac{1}{\left(\frac{A}{B}\right)}\cdot\frac{\left(\frac{B}{A}\right)}{\left(\frac{B}{A}\right)} = \frac{1\cdot\frac{B}{A}}{\frac{A}{B}\cdot\frac{B}{A}} = \frac{\frac{B}{A}}{\frac{AB}{BA}} = \frac{B}{A}\cdot\frac{1}{\frac{1}{1}} = \frac{B}{A}\cdot\frac{1}{1}= \frac{B}{A}")
}{\left(\frac{7}{2}\right)} = \frac{3}{4}\cdot\frac{1}{\left(\frac{7}{2}\right)} = \frac{3}{4}\cdot\frac{2}{7} = \frac{3\cdot2}{4\cdot7} = \frac{6}{28}") .
. .
.\frac{1}{\frac{1}{2}} = (x+7)\cdot2 = 2x+14")
\frac{C}{D} = \frac{A}{B} + \frac{(-1)C}{D} = \frac{AD}{BD} + \frac{(-1)BC}{BD} = \frac{AD+(-1)BC}{BD} = \frac{AD-BC}{BD}")

} = -\frac{1}{A}") .
. , you can get
, you can get ^n = \frac{A^n}{B^n}") .
.^{-n} = \left(\frac{B}{A}\right)^n") .
. , because it’s defined as the number that, when multiplied by 0, gives 1. But of course that number doesn’t exist*. In practice, if you ever see a “1/0”, stop mathing. And every time you divide by something that could be zero, make a note on the side of the paper. The short answer to almost every question about “1/0” is “doesn’t”.
, because it’s defined as the number that, when multiplied by 0, gives 1. But of course that number doesn’t exist*. In practice, if you ever see a “1/0”, stop mathing. And every time you divide by something that could be zero, make a note on the side of the paper. The short answer to almost every question about “1/0” is “doesn’t”. , then
, then  and by the way only when
and by the way only when  .
. , then you’re stuck. That’s as simplified as it can get. The one and only thing you can say about
, then you’re stuck. That’s as simplified as it can get. The one and only thing you can say about  = 3") (so long as
(so long as  ).
). , if you can figure out which of AD and BC is bigger (they’re both integers), then you can figure out which of
, if you can figure out which of AD and BC is bigger (they’re both integers), then you can figure out which of  and
and  is bigger.
is bigger.![\begin{array}{ll}\frac{7}{4}\,[?]\,\frac{5}{3}\\\Rightarrow 3\cdot4\cdot\frac{7}{4}\,[?]\,\frac{5}{3}\cdot3\cdot4\\\Rightarrow 3\cdot7\,[?]\,5\cdot4\\\Rightarrow 21\,[?]\,20\\\Rightarrow 21>20\\\Rightarrow\frac{7}{4}>\frac{5}{3}\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bll%7D%5Cfrac%7B7%7D%7B4%7D%5C%2C%5B%3F%5D%5C%2C%5Cfrac%7B5%7D%7B3%7D%5C%5C%5CRightarrow+3%5Ccdot4%5Ccdot%5Cfrac%7B7%7D%7B4%7D%5C%2C%5B%3F%5D%5C%2C%5Cfrac%7B5%7D%7B3%7D%5Ccdot3%5Ccdot4%5C%5C%5CRightarrow+3%5Ccdot7%5C%2C%5B%3F%5D%5C%2C5%5Ccdot4%5C%5C%5CRightarrow+21%5C%2C%5B%3F%5D%5C%2C20%5C%5C%5CRightarrow+21%3E20%5C%5C%5CRightarrow%5Cfrac%7B7%7D%7B4%7D%3E%5Cfrac%7B5%7D%7B3%7D%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{ll}\frac{7}{4}\,[?]\,\frac{5}{3}\\\Rightarrow 3\cdot4\cdot\frac{7}{4}\,[?]\,\frac{5}{3}\cdot3\cdot4\\\Rightarrow 3\cdot7\,[?]\,5\cdot4\\\Rightarrow 21\,[?]\,20\\\Rightarrow 21>20\\\Rightarrow\frac{7}{4}>\frac{5}{3}\end{array}")
 is just as far from 1 as it is from 0.
is just as far from 1 as it is from 0.  and
and  .
. . If for some horrifying, bizarre reason you find yourself looking at a string of numbers or variables being multiplied together, with no parentheses in sight, just replace “A/B” with “
. If for some horrifying, bizarre reason you find yourself looking at a string of numbers or variables being multiplied together, with no parentheses in sight, just replace “A/B” with “ ” and go*.
” and go*. .
.





{kind=link}