Physicist: Anti-matter is exactly the same as ordinary matter but opposite, in very much the same way that a left hand is exactly the same as a right hand… but opposite. Every anti-particle has exactly the same mass as their regular-particle counterparts, but with a bunch of their other characteristics flipped. For example, protons have an electric charge of +1 and a baryon number of +1. Anti-protons have an electric charge of -1 and a baryon number -1. The positive/negativeness of these numbers are irrelevant. A lot like left and right hands, the only thing that’s important about positive charges is that they’re the opposite of negative charges.
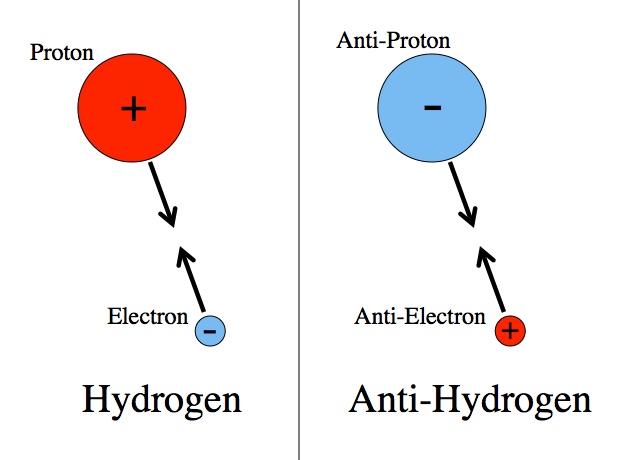
Hydrogen is stable because its constituent particles have opposite charges and opposites attract. Anti-hydrogen is stable for exactly the same reason.
Anti-matter acts, in (nearly) every way we can determine, exactly like matter. Light (which doesn’t have an anti-particle) interacts with one in exactly the same way as the other, so there’s no way to just look at something and know which is which. The one and only exception we’ve found so far is beta decay. In beta decay a neutron fires a new electron out of its “south pole”, whereas an anti-neutron fires an anti-electron out of its “north pole”. This is exactly the difference between left and right hands. Not a big deal.
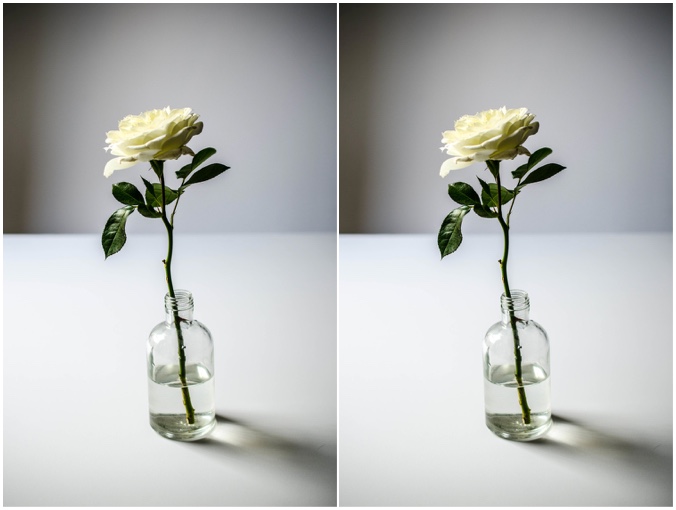
Left: A photograph of an actual flower made of regular matter. Right: An artistic representation of a flower made of anti-matter.
So when we look out into the universe and see stars and galaxies, there’s no way to tell which matter camp, regular or anti, that they fall into. Anti-stars would move and orbit the same way and produce light in exactly the same way as ordinary stars. Like the sign of electrical charge or the handedness of hands, the nature of matter and anti-matter are indistinguishable until you compare them.
But you have to be careful when you do, because when a particle comes into contact with its corresponding anti-particle, the two cancel out and dump all of their matter into energy (usually lots of light). If you were to casually grab hold of 1 kg of anti-matter, it (along with 1 kg of you) would release about the same amount of energy as the largest nuclear detonation in history.

The Tsar Bomba from 100 miles away. This is what 2 kg worth of energy can do (when released all at once).
To figure out exactly how much energy is tied up in matter (either kind), just use the little known relation between energy and matter: E=mc2. When you do, be sure to use standard units (kilograms for mass, meters and seconds for the speed of light, and Joules for energy) so that you don’t have to sweat the unit conversions. For 2 kg of matter, E = (2 kg)(3×108 m/s)2 = 1.8×1017 J.
When anti-matter and matter collide it’s hard to miss. We can’t tell whether a particular chunk of stuff is matter or anti-matter just by looking at it, but because we don’t regularly see stupendous space kablooies as nebulae collide with anti-nebulae, we can be sure that (at least in the observable universe) everything we see is regular matter. Or damn near everything. Our universe is a seriously unfriendly place for anti-matter.
So why would we even suspect that anti-matter exists? First, when you re-write Schrödinger’s equation (an excellent way to describe particles and whatnot) to make sense in the context of relativity (the fundamental nature of spacetime) you find that the equation that falls out has two solutions; a sort of left and right form for most kinds of particles (matter and anti-matter). Second, and more importantly, we can actually make anti-matter.
Very high energy situations, like those in particle accelerators, randomly generate new particles. But these new particles are always produced in balanced pairs; for every new proton (for example) there’s a new anti-proton. The nice thing about protons is that they have a charge and can be pushed around with magnets. Conveniently, anti-protons have the opposite charge and are pushed in the opposite direction by magnets. So, with tremendous cleverness and care, the shrapnel of high speed particle collisions can be collected and sorted. We can collect around a hundred million anti-particles at a time using particle accelerators (to create them) and particle decelerators (to stop and store them).
Anti-matter, it’s worth mentioning, is (presently) an absurd thing to build a weapon with. Considering that it takes the energy of a small town to run a decent particle accelerator, and that a mere hundred million anti-protons have all the destructive power of a single drop of rain, it’s just easier to throw a brick or something.
The highest energy particle interactions we can witness happen in the upper atmosphere; to see them we just have to be patient. The “Oh My God Particle” arrived from deep space with around ninety million times the energy of the particle beams in CERN, but we only see such ultra-high energy particles every few months and from dozens of miles away. We bothered to build CERN so we could see (comparatively feeble) particle collisions at our leisure and from really close up.
Those upper atmosphere collisions produce both matter and anti-matter, some tiny fraction of which ends up caught in the Van Allen radiation belts by the Earth’s magnetic field. In all, there are a few nanograms of anti-matter up there. Presumably, every planet and star with a sufficient and stable magnetic field has a tiny, tiny amount of anti-matter in orbit just like we do. So if you’re looking for all natural anti-matter, that’s the place to look.
But if anti-matter and matter are always created in equal amounts, and there’s no real difference between them (other than being different from each other), then why is all of the matter in the universe regular matter?
No one knows. It’s a total mystery. Isn’t that exciting? Baryon asymmetry is a wide open question and, not for lack of trying, we’ve got nothing.
The rose photo is from here.
Update: A commenter kindly pointed out that a little anti-matter is also produced during solar flares (which are definitively high-energy) and streams away from the Sun in solar wind.
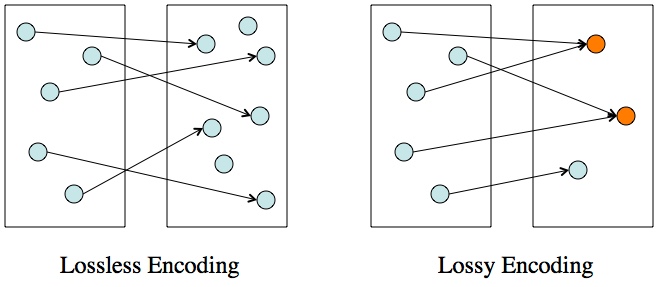
") . The entropy tells you both the average information per character and the highest density that can be achieved.
. The entropy tells you both the average information per character and the highest density that can be achieved. ,
,  , and
, and -\frac{1}{16}\log_2\left(\frac{1}{16}\right)\approx0.337") . That means that each digit only uses 0.337 bits on average. So a sequence like this (or one that goes on a lot longer) could be made about a third as long.
. That means that each digit only uses 0.337 bits on average. So a sequence like this (or one that goes on a lot longer) could be made about a third as long. and
and -\frac{1}{2}\log_2\left(\frac{1}{2}\right)=\frac{1}{2}+\frac{1}{2}=1") . In other words, each digit uses about 1 bit of information on average; this sequence is already about as dense as it can get.
. In other words, each digit uses about 1 bit of information on average; this sequence is already about as dense as it can get.

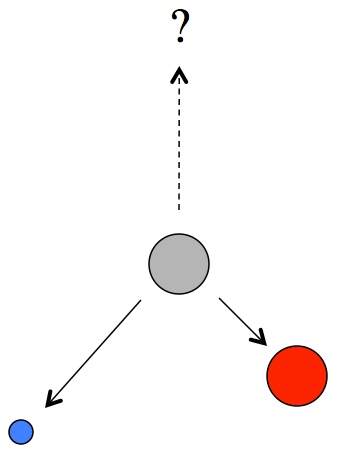
 , and immediately wondered: Why isn’t it infinity? How can it be a fraction? Wait… it’s negative?
, and immediately wondered: Why isn’t it infinity? How can it be a fraction? Wait… it’s negative? , then you’re right. Don’t let anyone tell you different. The
, then you’re right. Don’t let anyone tell you different. The  thing falls out of an obscure, if-it-applies-to-you-then-you-already-know-about-it, branch of mathematics called number theory.
thing falls out of an obscure, if-it-applies-to-you-then-you-already-know-about-it, branch of mathematics called number theory.=\sum_{n=1}^\infty\left(\frac{1}{n}\right)^s=1+\frac{1}{2^s}+\frac{1}{3^s}+\frac{1}{4^s}+\ldots") whenever this summation is equal to a number. If you plug s=-1 into
whenever this summation is equal to a number. If you plug s=-1 into =1+2+3+4+\ldots") , but in this case the summation isn’t a number (it’s infinity) so it’s not equal to
, but in this case the summation isn’t a number (it’s infinity) so it’s not equal to =-\frac{1}{12}") , however (and this is the crux of the issue), when you plug s=-1 into
, however (and this is the crux of the issue), when you plug s=-1 into  for s>1, but continues to exist and make sense long after the summation stops working.
for s>1, but continues to exist and make sense long after the summation stops working. , and
, and =1+\frac{1}{2}+\frac{1}{3}+\frac{1}{4}+\ldots=\infty") . It is absolutely reasonable to expect that for s<1,
. It is absolutely reasonable to expect that for s<1, =\sum_{n=1}^\infty\left(\frac{1}{n}\right)^s") when s>1 and as the “
when s>1 and as the “
 ). The only thing about complex numbers you’ll need to know here is that complex numbers are pairs of real numbers (regular numbers), A and B. Being a pair of numbers means that complex numbers form the “complex plane“, which is broader than the “real number line“. A is called the “real part”, often written A=Re[A+Bi], and B is the “imaginary part”, B=Im[A+Bi].
). The only thing about complex numbers you’ll need to know here is that complex numbers are pairs of real numbers (regular numbers), A and B. Being a pair of numbers means that complex numbers form the “complex plane“, which is broader than the “real number line“. A is called the “real part”, often written A=Re[A+Bi], and B is the “imaginary part”, B=Im[A+Bi].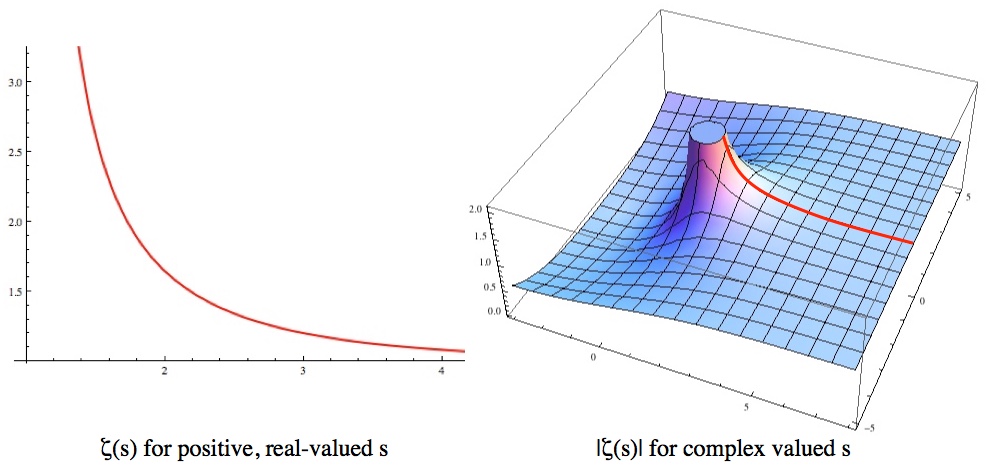
=1+\frac{1}{2^s}+\frac{1}{3^s}+\frac{1}{4^s}+\ldots") defines a nice,
defines a nice,  thing is entirely about math enthusiasts being so (justifiably) excited about ζ(s) that they misapply it, and has nothing to do with what 1+2+3+… actually equals.
thing is entirely about math enthusiasts being so (justifiably) excited about ζ(s) that they misapply it, and has nothing to do with what 1+2+3+… actually equals.=\sum_{n=0}^\infty z^n") only makes sense for -1<z<1, because it blows up at z=1 and doesn’t converge at z=-1.
only makes sense for -1<z<1, because it blows up at z=1 and doesn’t converge at z=-1.=\frac{1}{1-z}") . This clearly blows up at z=1, but is otherwise perfectly well behaved; the issues at z=-1 and beyond just vanish. f(z) and
. This clearly blows up at z=1, but is otherwise perfectly well behaved; the issues at z=-1 and beyond just vanish. f(z) and  are the same in every way inside of -1<z<1. The only difference is that
are the same in every way inside of -1<z<1. The only difference is that ![\begin{array}{ll} &\left(1-2^{1-s}\right)\zeta(s)\\[2mm] =&\left(1-2^{1-s}\right)\sum_{n=1}^\infty\frac{1}{n^s}\\[2mm] =&\sum_{n=1}^\infty\frac{1}{n^s}-2^{1-s}\sum_{n=1}^\infty\frac{1}{n^s}\\[2mm] =&\sum_{n=1}^\infty\frac{1}{n^s}-2\sum_{n=1}^\infty\frac{1}{(2n)^s}\\[2mm] =&\left(\frac{1}{1^s}+\frac{1}{2^s}+\frac{1}{3^s}+\frac{1}{4^s}+\ldots\right)-2\left(\frac{1}{2^s}+\frac{1}{4^s}+\frac{1}{6^s}+\frac{1}{8^s}+\ldots\right)\\[2mm] =&\frac{1}{1^s}-\frac{1}{2^s}+\frac{1}{3^s}-\frac{1}{4^s}+\ldots\\[2mm] =&\sum_{n=1}^\infty\frac{(-1)^{n-1}}{n^s}\\[2mm] =&\sum_{n=0}^\infty\frac{(-1)^{n}}{(n+1)^s} \end{array}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bll%7D++++%26%5Cleft%281-2%5E%7B1-s%7D%5Cright%29%5Czeta%28s%29%5C%5C%5B2mm%5D++%3D%26%5Cleft%281-2%5E%7B1-s%7D%5Cright%29%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B1%7D%7Bn%5Es%7D%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B1%7D%7Bn%5Es%7D-2%5E%7B1-s%7D%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B1%7D%7Bn%5Es%7D%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B1%7D%7Bn%5Es%7D-2%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%282n%29%5Es%7D%5C%5C%5B2mm%5D++%3D%26%5Cleft%28%5Cfrac%7B1%7D%7B1%5Es%7D%2B%5Cfrac%7B1%7D%7B2%5Es%7D%2B%5Cfrac%7B1%7D%7B3%5Es%7D%2B%5Cfrac%7B1%7D%7B4%5Es%7D%2B%5Cldots%5Cright%29-2%5Cleft%28%5Cfrac%7B1%7D%7B2%5Es%7D%2B%5Cfrac%7B1%7D%7B4%5Es%7D%2B%5Cfrac%7B1%7D%7B6%5Es%7D%2B%5Cfrac%7B1%7D%7B8%5Es%7D%2B%5Cldots%5Cright%29%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B1%7D%7B1%5Es%7D-%5Cfrac%7B1%7D%7B2%5Es%7D%2B%5Cfrac%7B1%7D%7B3%5Es%7D-%5Cfrac%7B1%7D%7B4%5Es%7D%2B%5Cldots%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bn%3D1%7D%5E%5Cinfty%5Cfrac%7B%28-1%29%5E%7Bn-1%7D%7D%7Bn%5Es%7D%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B%28-1%29%5E%7Bn%7D%7D%7B%28n%2B1%29%5Es%7D++%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0 "\begin{array}{ll} &\left(1-2^{1-s}\right)\zeta(s)\\[2mm] =&\left(1-2^{1-s}\right)\sum_{n=1}^\infty\frac{1}{n^s}\\[2mm] =&\sum_{n=1}^\infty\frac{1}{n^s}-2^{1-s}\sum_{n=1}^\infty\frac{1}{n^s}\\[2mm] =&\sum_{n=1}^\infty\frac{1}{n^s}-2\sum_{n=1}^\infty\frac{1}{(2n)^s}\\[2mm] =&\left(\frac{1}{1^s}+\frac{1}{2^s}+\frac{1}{3^s}+\frac{1}{4^s}+\ldots\right)-2\left(\frac{1}{2^s}+\frac{1}{4^s}+\frac{1}{6^s}+\frac{1}{8^s}+\ldots\right)\\[2mm] =&\frac{1}{1^s}-\frac{1}{2^s}+\frac{1}{3^s}-\frac{1}{4^s}+\ldots\\[2mm] =&\sum_{n=1}^\infty\frac{(-1)^{n-1}}{n^s}\\[2mm] =&\sum_{n=0}^\infty\frac{(-1)^{n}}{(n+1)^s} \end{array}")
=\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{(-1)^{n}}{(n+1)^s}") , that is an analytic continuation because this new sum converges in the same region the original form did (s>1), plus a little more (0<s≤1). Notice that while the summation no longer blows up at s=1,
, that is an analytic continuation because this new sum converges in the same region the original form did (s>1), plus a little more (0<s≤1). Notice that while the summation no longer blows up at s=1,  does. Analytic continuation won’t get rid of poles, but it can express them differently.
does. Analytic continuation won’t get rid of poles, but it can express them differently.^{n+1}}=1") for any y. This is not obvious. Being equal to one means that you can pop this into the middle of anything. If that thing happens to be another sum, it can be used to make that sum “more convergent” for some values of y. Take any sum,
for any y. This is not obvious. Being equal to one means that you can pop this into the middle of anything. If that thing happens to be another sum, it can be used to make that sum “more convergent” for some values of y. Take any sum,  , insert Euler’s sum, and swap the order of summation:
, insert Euler’s sum, and swap the order of summation:![\begin{array}{rcl} \sum_{k=0}^\infty A_k&=&\sum_{k=0}^\infty \left(\sum_{n=k}^\infty {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}\right)A_k\\[2mm] &=&\sum_{k=0}^\infty \sum_{n=k}^\infty {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}A_k\\[2mm] &=&\sum_{n=0}^\infty \sum_{k=0}^n {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}A_k\\[2mm] &=&\sum_{n=0}^\infty \frac{1}{(1+y)^{n+1}}\sum_{k=0}^n {n\choose k}y^{k+1}A_k\\[2mm] \end{array}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D++%5Csum_%7Bk%3D0%7D%5E%5Cinfty+A_k%26%3D%26%5Csum_%7Bk%3D0%7D%5E%5Cinfty+%5Cleft%28%5Csum_%7Bn%3Dk%7D%5E%5Cinfty+%7Bn%5Cchoose+k%7D%5Cfrac%7By%5E%7Bk%2B1%7D%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7D%5Cright%29A_k%5C%5C%5B2mm%5D++%26%3D%26%5Csum_%7Bk%3D0%7D%5E%5Cinfty+%5Csum_%7Bn%3Dk%7D%5E%5Cinfty+%7Bn%5Cchoose+k%7D%5Cfrac%7By%5E%7Bk%2B1%7D%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7DA_k%5C%5C%5B2mm%5D++%26%3D%26%5Csum_%7Bn%3D0%7D%5E%5Cinfty+%5Csum_%7Bk%3D0%7D%5En+%7Bn%5Cchoose+k%7D%5Cfrac%7By%5E%7Bk%2B1%7D%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7DA_k%5C%5C%5B2mm%5D++%26%3D%26%5Csum_%7Bn%3D0%7D%5E%5Cinfty+%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En+%7Bn%5Cchoose+k%7Dy%5E%7Bk%2B1%7DA_k%5C%5C%5B2mm%5D++%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0 "\begin{array}{rcl} \sum_{k=0}^\infty A_k&=&\sum_{k=0}^\infty \left(\sum_{n=k}^\infty {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}\right)A_k\\[2mm] &=&\sum_{k=0}^\infty \sum_{n=k}^\infty {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}A_k\\[2mm] &=&\sum_{n=0}^\infty \sum_{k=0}^n {n\choose k}\frac{y^{k+1}}{(1+y)^{n+1}}A_k\\[2mm] &=&\sum_{n=0}^\infty \frac{1}{(1+y)^{n+1}}\sum_{k=0}^n {n\choose k}y^{k+1}A_k\\[2mm] \end{array}")
![\begin{array}{rcl} \zeta(s)&=&\frac{1}{1-2^{1-s}}\sum_{k=0}^\infty\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{(1+y)^{n+1}}\sum_{k=0}^n{n\choose k}y^{k+1}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{(1+1)^{n+1}}\sum_{k=0}^n{n\choose k}1^{k+1}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] \end{array}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D++%5Czeta%28s%29%26%3D%26%5Cfrac%7B1%7D%7B1-2%5E%7B1-s%7D%7D%5Csum_%7Bk%3D0%7D%5E%5Cinfty%5Cfrac%7B%28-1%29%5E%7Bk%7D%7D%7B%28k%2B1%29%5Es%7D%5C%5C%5B2mm%5D++%26%3D%26%5Cfrac%7B1%7D%7B1-2%5E%7B1-s%7D%7D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En%7Bn%5Cchoose+k%7Dy%5E%7Bk%2B1%7D%5Cfrac%7B%28-1%29%5E%7Bk%7D%7D%7B%28k%2B1%29%5Es%7D%5C%5C%5B2mm%5D++%26%3D%26%5Cfrac%7B1%7D%7B1-2%5E%7B1-s%7D%7D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%281%2B1%29%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En%7Bn%5Cchoose+k%7D1%5E%7Bk%2B1%7D%5Cfrac%7B%28-1%29%5E%7Bk%7D%7D%7B%28k%2B1%29%5Es%7D%5C%5C%5B2mm%5D++%26%3D%26%5Cfrac%7B1%7D%7B1-2%5E%7B1-s%7D%7D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B2%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En%7Bn%5Cchoose+k%7D%5Cfrac%7B%28-1%29%5E%7Bk%7D%7D%7B%28k%2B1%29%5Es%7D%5C%5C%5B2mm%5D++%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0 "\begin{array}{rcl} \zeta(s)&=&\frac{1}{1-2^{1-s}}\sum_{k=0}^\infty\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{(1+y)^{n+1}}\sum_{k=0}^n{n\choose k}y^{k+1}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{(1+1)^{n+1}}\sum_{k=0}^n{n\choose k}1^{k+1}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] &=&\frac{1}{1-2^{1-s}}\sum_{n=0}^\infty\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}\frac{(-1)^{k}}{(k+1)^s}\\[2mm] \end{array}")
^{k}k^d=0") . This means that for negative integer values of s, that infinite sum suddenly becomes finite because all but a handful of terms are zero.
. This means that for negative integer values of s, that infinite sum suddenly becomes finite because all but a handful of terms are zero.![\begin{array}{rcl} \zeta(-1)&=&\frac{1}{1-2^{2}}\sum_{n=0}^\infty\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}(-1)^{k}(k+1)\\[2mm] &=&-\frac{1}{3}\sum_{n=0}^1\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}(-1)^{k}(k+1)\\[2mm] &=&-\frac{1}{3}\cdot\frac{1}{2^{0+1}}{0\choose 0}(-1)^{0}(0+1)-\frac{1}{3}\cdot\frac{1}{2^{1+1}}{1\choose 0}(-1)^{0}(0+1)-\frac{1}{3}\cdot\frac{1}{2^{1+1}}{1\choose 1}(-1)^{1}(1+1)\\[2mm] &=&-\frac{1}{3}\cdot\frac{1}{2}\cdot1\cdot1\cdot1-\frac{1}{3}\cdot\frac{1}{4}\cdot1\cdot1\cdot1-\frac{1}{3}\cdot\frac{1}{4}\cdot1\cdot(-1)\cdot2\\[2mm] &=&-\frac{1}{6}-\frac{1}{12}+\frac{1}{6}\\[2mm] &=&-\frac{1}{12} \end{array}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D++%5Czeta%28-1%29%26%3D%26%5Cfrac%7B1%7D%7B1-2%5E%7B2%7D%7D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B2%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En%7Bn%5Cchoose+k%7D%28-1%29%5E%7Bk%7D%28k%2B1%29%5C%5C%5B2mm%5D++%26%3D%26-%5Cfrac%7B1%7D%7B3%7D%5Csum_%7Bn%3D0%7D%5E1%5Cfrac%7B1%7D%7B2%5E%7Bn%2B1%7D%7D%5Csum_%7Bk%3D0%7D%5En%7Bn%5Cchoose+k%7D%28-1%29%5E%7Bk%7D%28k%2B1%29%5C%5C%5B2mm%5D++%26%3D%26-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B2%5E%7B0%2B1%7D%7D%7B0%5Cchoose+0%7D%28-1%29%5E%7B0%7D%280%2B1%29-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B2%5E%7B1%2B1%7D%7D%7B1%5Cchoose+0%7D%28-1%29%5E%7B0%7D%280%2B1%29-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B2%5E%7B1%2B1%7D%7D%7B1%5Cchoose+1%7D%28-1%29%5E%7B1%7D%281%2B1%29%5C%5C%5B2mm%5D++%26%3D%26-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B2%7D%5Ccdot1%5Ccdot1%5Ccdot1-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B4%7D%5Ccdot1%5Ccdot1%5Ccdot1-%5Cfrac%7B1%7D%7B3%7D%5Ccdot%5Cfrac%7B1%7D%7B4%7D%5Ccdot1%5Ccdot%28-1%29%5Ccdot2%5C%5C%5B2mm%5D++%26%3D%26-%5Cfrac%7B1%7D%7B6%7D-%5Cfrac%7B1%7D%7B12%7D%2B%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B2mm%5D++%26%3D%26-%5Cfrac%7B1%7D%7B12%7D++%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0 "\begin{array}{rcl} \zeta(-1)&=&\frac{1}{1-2^{2}}\sum_{n=0}^\infty\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}(-1)^{k}(k+1)\\[2mm] &=&-\frac{1}{3}\sum_{n=0}^1\frac{1}{2^{n+1}}\sum_{k=0}^n{n\choose k}(-1)^{k}(k+1)\\[2mm] &=&-\frac{1}{3}\cdot\frac{1}{2^{0+1}}{0\choose 0}(-1)^{0}(0+1)-\frac{1}{3}\cdot\frac{1}{2^{1+1}}{1\choose 0}(-1)^{0}(0+1)-\frac{1}{3}\cdot\frac{1}{2^{1+1}}{1\choose 1}(-1)^{1}(1+1)\\[2mm] &=&-\frac{1}{3}\cdot\frac{1}{2}\cdot1\cdot1\cdot1-\frac{1}{3}\cdot\frac{1}{4}\cdot1\cdot1\cdot1-\frac{1}{3}\cdot\frac{1}{4}\cdot1\cdot(-1)\cdot2\\[2mm] &=&-\frac{1}{6}-\frac{1}{12}+\frac{1}{6}\\[2mm] &=&-\frac{1}{12} \end{array}")
^{k+1}}") . There are a couple ways to do that, but
. There are a couple ways to do that, but \sum_{j=k+1}^M g_j")
 , shows up on each side. Knowing about
, shows up on each side. Knowing about  is all we need to unravel this sum.
is all we need to unravel this sum.![\begin{array}{rl} &\sum_{k=n}^\infty{k\choose n}\frac{1}{(1+y)^{k+1}}\\[2mm] =&{n\choose n}\sum_{k=n}^\infty\frac{1}{(1+y)^{k+1}}+\sum_{k=n}^\infty\left({k+1\choose n}-{k\choose n}\right)\sum_{j=k+1}^\infty \frac{1}{(1+y)^{j+1}}\\[2mm] =&\sum_{k=n}^\infty\frac{1}{(1+y)^{k+1}}+\sum_{k=n}^\infty{k\choose n-1}\sum_{j=k+1}^\infty \frac{1}{(1+y)^{j+1}}\\[2mm] =&\frac{\frac{1}{(1+y)^{n+1}}}{1-\frac{1}{(1+y)}}+\sum_{k=n}^\infty{k\choose n-1}\frac{\frac{1}{(1+y)^{k+2}}}{1-\frac{1}{(1+y)}}\\[2mm] =&\frac{1}{y(1+y)^n}+\sum_{k=n}^\infty{k\choose n-1}\frac{1}{y(1+y)^{k+1}}\\[2mm] =&\sum_{k=n-1}^\infty{k\choose n-1}\frac{1}{y(1+y)^{k+1}}\\[2mm] =&\cdots\\[2mm] =&\sum_{k=0}^\infty{k\choose 0}\frac{1}{y^n(1+y)^{k+1}}\\[2mm] =&\frac{1}{y^n}\sum_{k=0}^\infty\frac{1}{(1+y)^{k+1}}\\[2mm] =&\frac{1}{y^n}\frac{\frac{1}{(1+y)}}{1-\frac{1}{(1+y)}}\\[2mm] =&\frac{1}{y^{n+1}} \end{array}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7D++%26%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%7Bk%5Cchoose+n%7D%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bk%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%7Bn%5Cchoose+n%7D%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bk%2B1%7D%7D%2B%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%5Cleft%28%7Bk%2B1%5Cchoose+n%7D-%7Bk%5Cchoose+n%7D%5Cright%29%5Csum_%7Bj%3Dk%2B1%7D%5E%5Cinfty+%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bj%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bk%2B1%7D%7D%2B%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%7Bk%5Cchoose+n-1%7D%5Csum_%7Bj%3Dk%2B1%7D%5E%5Cinfty+%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bj%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bn%2B1%7D%7D%7D%7B1-%5Cfrac%7B1%7D%7B%281%2By%29%7D%7D%2B%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%7Bk%5Cchoose+n-1%7D%5Cfrac%7B%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bk%2B2%7D%7D%7D%7B1-%5Cfrac%7B1%7D%7B%281%2By%29%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B1%7D%7By%281%2By%29%5En%7D%2B%5Csum_%7Bk%3Dn%7D%5E%5Cinfty%7Bk%5Cchoose+n-1%7D%5Cfrac%7B1%7D%7By%281%2By%29%5E%7Bk%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bk%3Dn-1%7D%5E%5Cinfty%7Bk%5Cchoose+n-1%7D%5Cfrac%7B1%7D%7By%281%2By%29%5E%7Bk%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Ccdots%5C%5C%5B2mm%5D++%3D%26%5Csum_%7Bk%3D0%7D%5E%5Cinfty%7Bk%5Cchoose+0%7D%5Cfrac%7B1%7D%7By%5En%281%2By%29%5E%7Bk%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B1%7D%7By%5En%7D%5Csum_%7Bk%3D0%7D%5E%5Cinfty%5Cfrac%7B1%7D%7B%281%2By%29%5E%7Bk%2B1%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B1%7D%7By%5En%7D%5Cfrac%7B%5Cfrac%7B1%7D%7B%281%2By%29%7D%7D%7B1-%5Cfrac%7B1%7D%7B%281%2By%29%7D%7D%5C%5C%5B2mm%5D++%3D%26%5Cfrac%7B1%7D%7By%5E%7Bn%2B1%7D%7D++%5Cend%7Barray%7D&bg=ffffff&fg=000&s=0 "\begin{array}{rl} &\sum_{k=n}^\infty{k\choose n}\frac{1}{(1+y)^{k+1}}\\[2mm] =&{n\choose n}\sum_{k=n}^\infty\frac{1}{(1+y)^{k+1}}+\sum_{k=n}^\infty\left({k+1\choose n}-{k\choose n}\right)\sum_{j=k+1}^\infty \frac{1}{(1+y)^{j+1}}\\[2mm] =&\sum_{k=n}^\infty\frac{1}{(1+y)^{k+1}}+\sum_{k=n}^\infty{k\choose n-1}\sum_{j=k+1}^\infty \frac{1}{(1+y)^{j+1}}\\[2mm] =&\frac{\frac{1}{(1+y)^{n+1}}}{1-\frac{1}{(1+y)}}+\sum_{k=n}^\infty{k\choose n-1}\frac{\frac{1}{(1+y)^{k+2}}}{1-\frac{1}{(1+y)}}\\[2mm] =&\frac{1}{y(1+y)^n}+\sum_{k=n}^\infty{k\choose n-1}\frac{1}{y(1+y)^{k+1}}\\[2mm] =&\sum_{k=n-1}^\infty{k\choose n-1}\frac{1}{y(1+y)^{k+1}}\\[2mm] =&\cdots\\[2mm] =&\sum_{k=0}^\infty{k\choose 0}\frac{1}{y^n(1+y)^{k+1}}\\[2mm] =&\frac{1}{y^n}\sum_{k=0}^\infty\frac{1}{(1+y)^{k+1}}\\[2mm] =&\frac{1}{y^n}\frac{\frac{1}{(1+y)}}{1-\frac{1}{(1+y)}}\\[2mm] =&\frac{1}{y^{n+1}} \end{array}")